雜談
因為在新手訓練時間不能回覆他人的留言,導致我不能回覆Day9的邦友回覆(甚至試了兩次QQ)。
在此說明一下:標題會提到Vectorized Functions是因為在dplyr的cheatsheet有提到mutate()可以搭配Vectorized Functions使用,包括lag()及lead()等等,所以就直接採用這個說法。不過我在Day10在查內容時,也有看Window Function的說法,這部分我找時間確認一下再進行修正,感謝obarisk邦友的回覆。
正文
今天來紀錄Ranking相關內容:
dplyr::cume_dist(): 大於等於此值的數量除以所有資料量的比例
dplyr::dense_rank(): 由小到大的排名(名次連續,若有兩個第一名,則數值排名第二的會是第二名)
dplyr::min_rank(): 由小到大的排名(名次連續,若有兩個第一名,則數值排名第二的會是第三名)
dplyr::ntile(): 分成n組
dplyr::percent_rank(): min_rank()的方法,不過數值縮放成0到1的數值
dplyr::row_number(): 給予每個資料的獨特排名
先比較row_number()、min_rank()及dense_rank()的差異
x <- c(5, 1, 3, 2, 2, NA)
row_number(x)
min_rank(x)相同數值會是同樣排名,但名次不連續,故為
dense_rank(x)

row_number(x)每個都是獨特的排名,故為(5,1,4,2,3,NA)
min_rank(x)相同數值會是同樣排名,但名次不連續,故為(5,1,4,2,2,NA)
dense_rank(x)相同數值會是同樣排名,名次連續,故為(4,1,3,2,2,NA)
接著利用mtcars進行測試這些函式
mtcars |> mutate(,cume_dist(mpg))
Toyota Corolla 為最大值,故為1.00000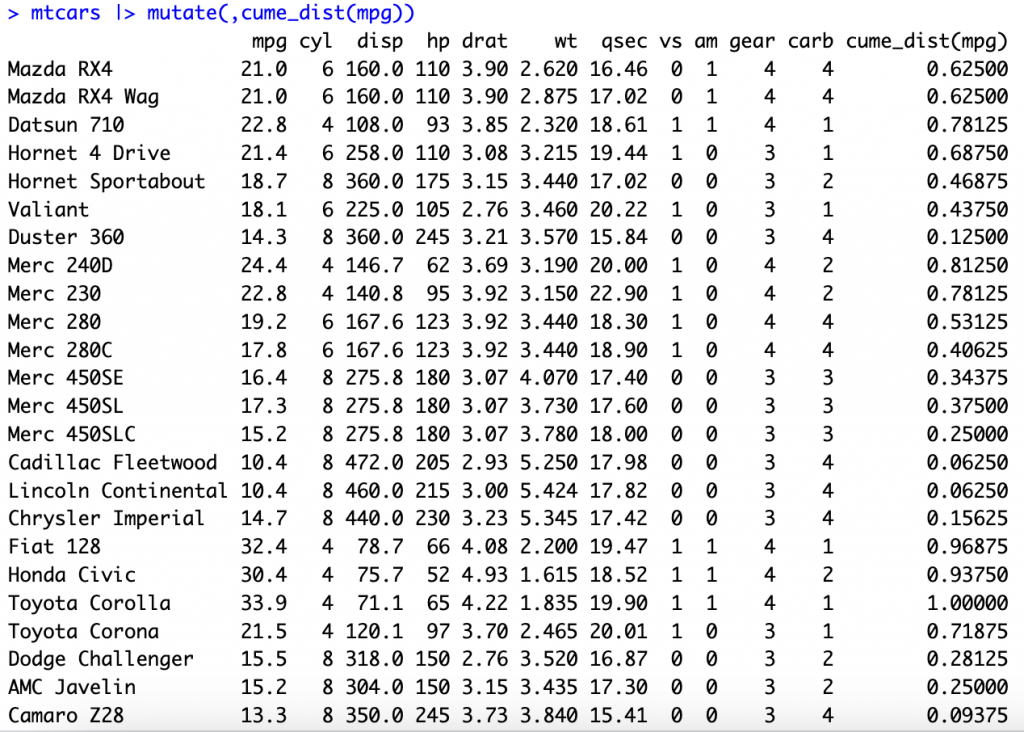
將mpg依照大小分成4組
mtcars |> mutate(,ntile(mpg,4))
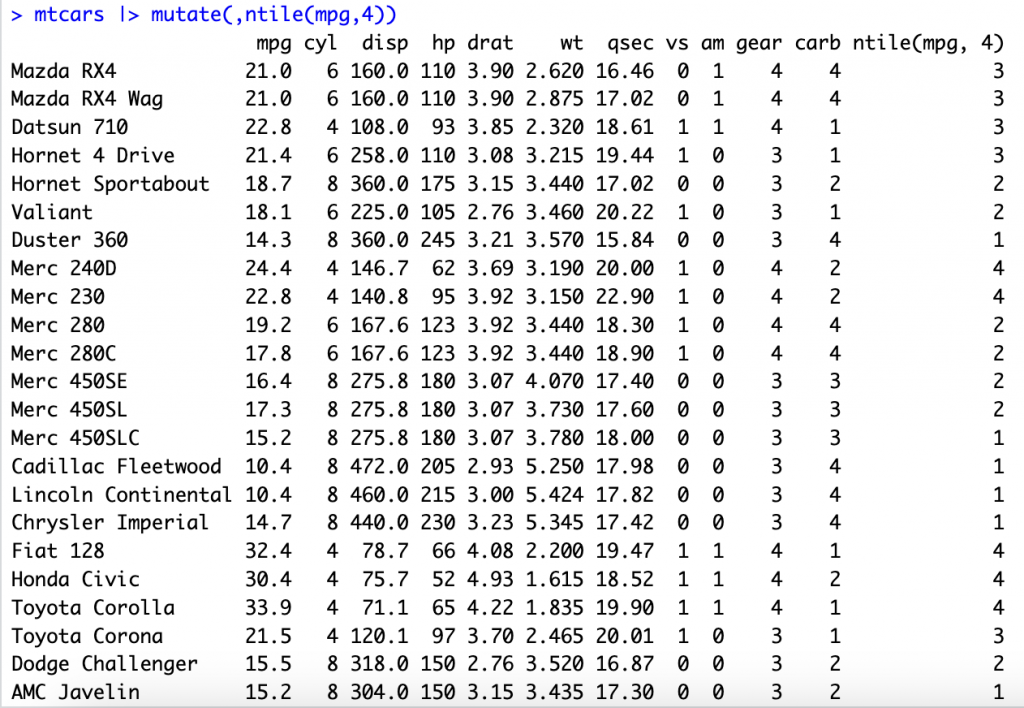
今天的小筆記就先到這邊,大家明天見~~
參考資料:
那這邊的 "Vectorized Function",跟我指的 "Vectorized Function" 是不同
在 R 裡面,向量化可以指
a. 用 C/C++ 加速的迴圈計算。
舉個例子,R 的矩陣乘法是"向量化"計算。
m <- matrix(1:4, 2, 2)
m %*% m
如果用 R 寫一個迴圈做矩陣乘法,那就不是向量化
b. Vectorize 函數包裝的函數。
library("dplyr")
wedate <- function(s) {
v <- strsplit(s, "-")
sprintf("%d-%s-%s", as.numeric(v[[1]][1]) + 1911, v[[1]][2], v[[1]][3])
}
vwedate <- Vectorize(wedate)
da <- data.frame(
twdates = c("113-09-01", "113-08-01")
)
# 這會算錯,我印象中以前會出錯誤訊息,
# 但是剛剛測試 (R 4.4.1),不會出錯誤訊息,只會計算錯誤 Orz
da |>
mutate(date = wedate(twdates))
# 2024-09-01, 2024-09-01
# 這才會對
da |>
mutate(date = vwedate(twdates))
# 2024-09-01, 2024-08-01

